
Abstract
Dense Video Object Captioning (DVOC) is the task of jointly detecting, tracking, and captioning object trajectories in a video, requiring the ability to understand spatio-temporal details and describe them in natural language. Due to the complexity of the task and the high cost associated with manual annotation, previous approaches resort to disjoint training strategies, potentially leading to suboptimal performance. To circumvent this issue, we propose to generate captions about spatio-temporally localized entities leveraging a state-of-the-art VLM. By extending the LVIS and LV-VIS datasets with our synthetic captions (LVISCap and LV-VISCap), we train CaptionFormer, an end-to-end model capable of jointly detecting, segmenting, tracking and captioning object trajectories. Moreover, with pretraining on LVISCap and LV-VISCap, CaptionFormer achieves state-of-the-art DVOC results on three existing benchmarks, VidSTG, VLN and BenSMOT.
Annotation pipeline
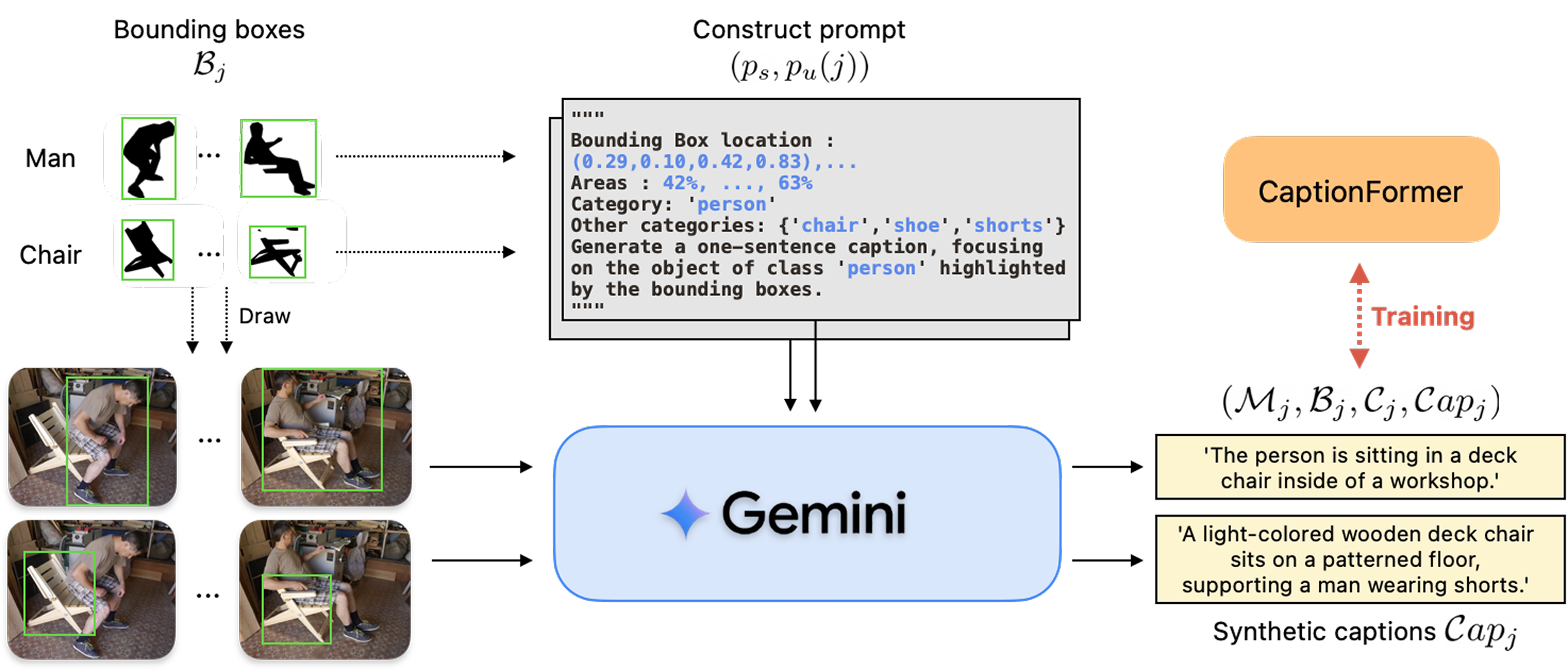
Our CaptionFormer data annotation pipeline. We use this pipeline to generate the LVISCap and LV-VISCap datasets, which serve to train CaptionFormer. To generate object-level captions, we feed both a visual prompt and a text prompt to a VLM (Gemini 2.0 flash).

Some synthetic annotations examples from our proposed LV-VICap dataset.
CaptionFormer Architecture
Overview of our CaptionFormer architecture. Videos are divided into clips that are processed sequentially in a semi-online manner. After generating queries and predictions for each object within a clip, tracking and captioning can be performed at the video level.
Quantitative results
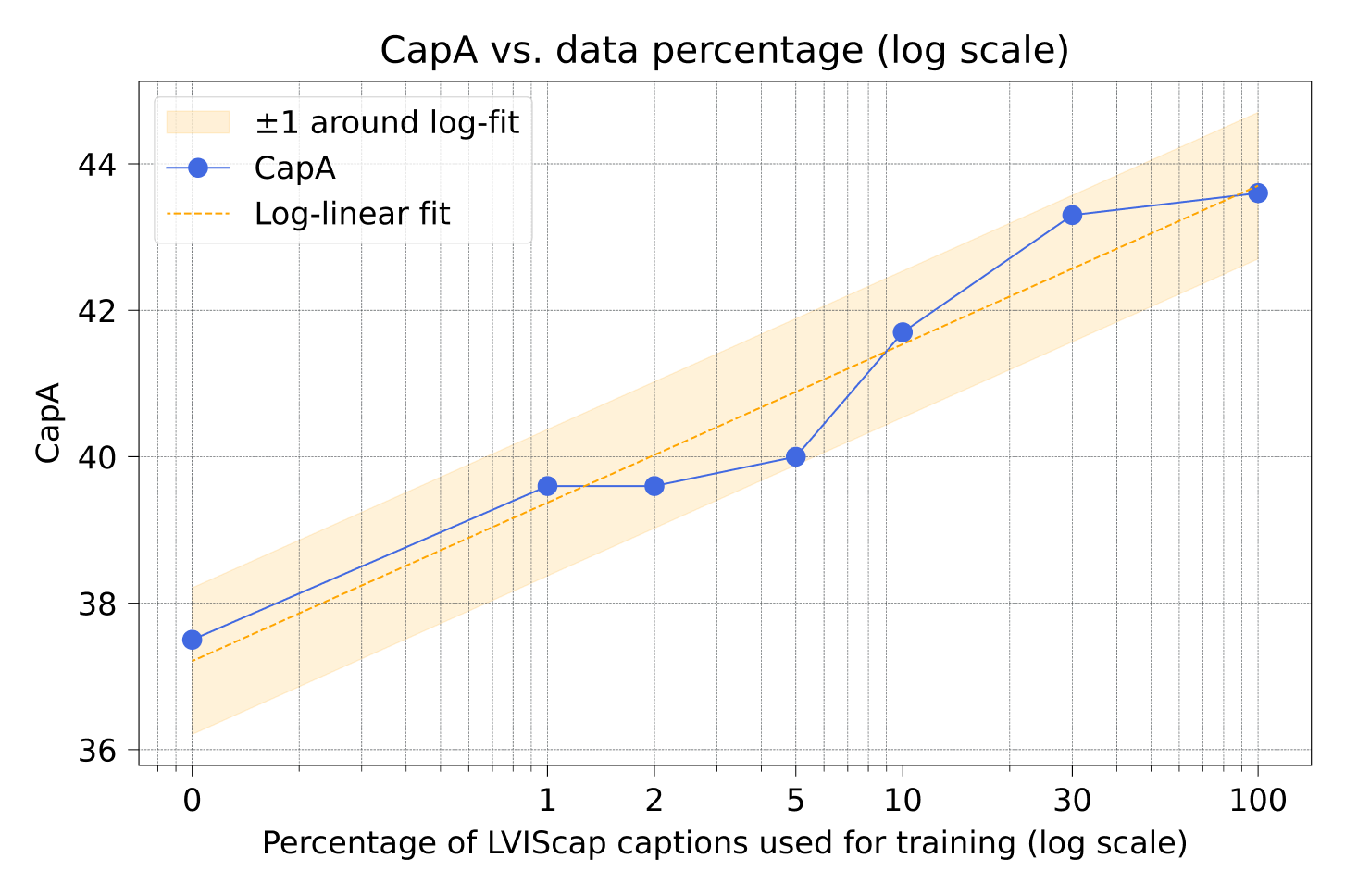
Our data helps! Captioning performance (CapA) scales log-linearly with the amount of our synthetic LVISCap captions used for training, highlighting the value of our generated data.
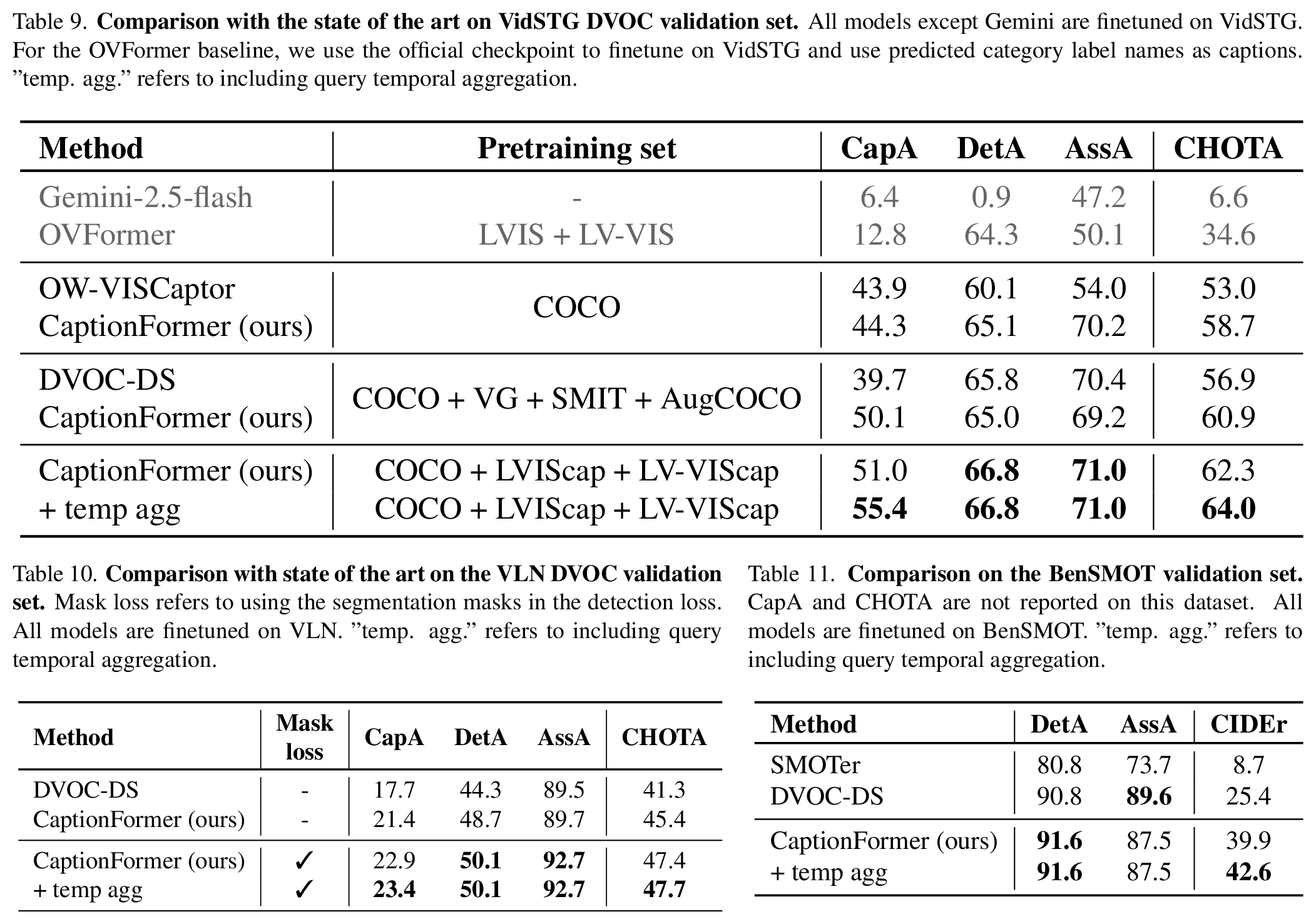
CaptionFormer achieves state of the art DVOC results on the VidSTG, VLN and BenSMOT benchmarks with pre-training on our LVIScap and LV-VIScap datasets.

Qualitative result on LV-VIS. CaptionFormer is the first end-to-end model to produce (mask, box, caption) trajectories for all objects in a video.
BibTeX
@inproceedings{fiastre2026captionformer,
title = {CaptionFormer: Unified Segmentation, Tracking, and Captioning for Spatio-Temporal Objects},
author = {Gabriel Fiastre and Antoine Yang and Cordelia Schmid},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2026}
}